📊 ソーシャルリスニング実践|Threads × キーワード収集 × ばけばけ 編
📋 この記事のポイント
2026年3月まで多くの視聴者を魅了したNHK朝ドラ「ばけばけ」は、放送中からネット上で多くの高評価コメントが投稿されました。そして最終回の放送終了後の現在も、その余韻が続いています。
例えば、島根県松江市の市役所に、ドラマのセットが再現された展示が設けられた際には、SNSのThreadsにはその展示を訪れた人たちの報告が次々と流れてきて、松野家の長屋の狭さに驚いたり、涙をこらえながら写真を撮ったりした体験が、熱量を持って語られています。
また別の投稿では、「ばけばけロス」を癒やすためにサントラを聴きながら料理したという日常の一コマが綴られています。たまたま目にした「ばけばけ」の世界観につながる商品を、思わず手に取ってしまったという人もいます。
なぜドラマが終わった後も、豊かな言葉と行動が生まれ続けているのか。このような問いに答えるのに、「満足度は何点ですか?」というアンケートは向いていません。
そこで今回はソーシャルリスニングという手法を通じて、ドラマ視聴者の声や行動を掘り下げてみたいと思います。
ソーシャルリスニングとは?
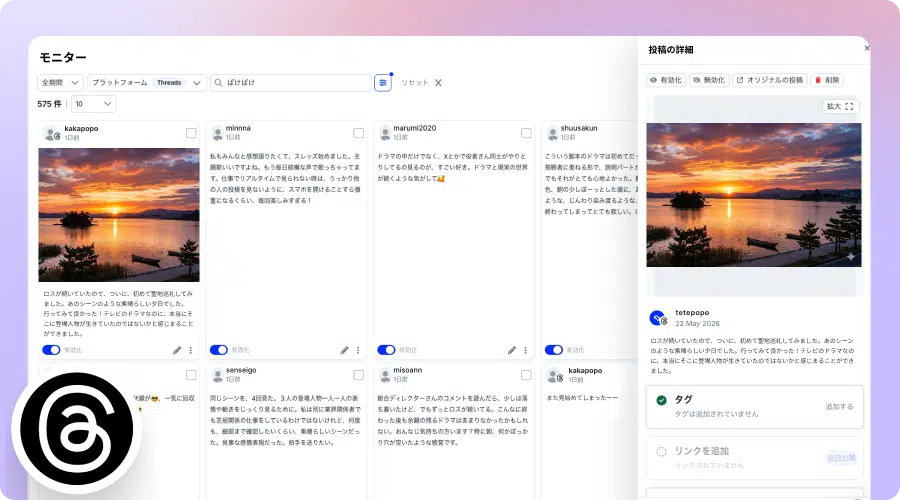
SNS上のキーワードを含む公開投稿を収集・観察し、熱量の深さや行動の文脈を読み解くリサーチ手法です。アンケートが「何%が満足したか」という割合を測るのに対し、ソーシャルリスニングは「どう満足したか・それがどんな行動を生んだか」という熱量と文脈を読みます。UGC・ソーシャルリスニングツールのEmbedSocialのThreadsキーワード収集機能を使えば、指定したキーワードを含む公開投稿を自動で蓄積し、インサイト分析からUGC活用まで一気通貫で行えます。
→ ソーシャルリスニングのやり方・基本ガイド
ブランドや商品の評判を調べたいとき、最初に思い浮かぶのはアンケート調査かもしれません。アンケートは「何%が満足したか」「どの年代に支持されているか」といった全体像を数値で把握するのに優れた手法です。
ただし、アンケートには構造的な限界があります。回答者は「設問の枠組み」に沿って答えます。そこに現れるのは整理された意見であって、「松江まで行ってしまった理由」や「料理を仕込みながら泣いた文脈」ではありません。文化人類学の手法をデジタルに応用した「デジタル・エスノグラフィー」の領域では、「人はアンケートには建前を書くが、SNSには欲望をそのまま吐き出す」と言われます。自発的な発話の中にこそ、加工されていない熱量があります(参考:QuestionPro「Surveys vs. Social Listening」)。
こうした背景から注目されているのがソーシャルリスニングです。SNS上の自然な会話を観察し、熱量の深さと文脈を読み解くリサーチ手法です。アンケートと対立するものではなく、「割合を測る」アンケートと「熱量を読む」ソーシャルリスニングは、互いを補う関係にあります。NTTデータ経営研究所の調査レポートでも、顧客の声を「企業が能動的に収集するAsk型」と「顧客が自発的に発する声を傾聴するListen型」に分類し、CX向上には両者の組み合わせが不可欠だと指摘されています(参考:NTTデータ経営研究所「顧客の声を活用したCX向上の要諦」)。
ソーシャルリスニングには「強い感情を持つ人ほど発言する」という発話バイアスがあります。つまり、収集できるデータは世論の平均値ではありません。その偏りを知った上で読むことが、このリサーチ手法の前提になります。
今回の分析には、EmbedSocialのThreadsキーワード収集機能を使用しました。Threads Keyword Search APIを通じて、「ばけばけ」というキーワードを含む公開投稿を自動収集し、データを蓄積しています。
ソーシャルリスニングには「どのプラットフォームで」「どの方法で」収集するかという2つの設計軸があります。今回はThreads × キーワード収集という方法を選んでみましたが、リスニングの目的に合っていた、というのが理由です。
軸①:プラットフォームの選択(Threads vs X / Instagram)
「熱量の質を読む」という目的においては、一件一件の密度が高いThreadsが向いていると判断し、今回はThreadsで投稿を集めることにしました。しかし、同じ「ばけばけ」でもXのハッシュタグ投稿を分析すれば異なる傾向のデータが得られるかもしれません。同じテーマで複数のプラットフォームの投稿を比較するというのも面白いでしょう。
つまり、プラットフォームの選択自体がリスニングの設計となるのです。
軸②:収集方法の選択(キーワード vs ハッシュタグ)
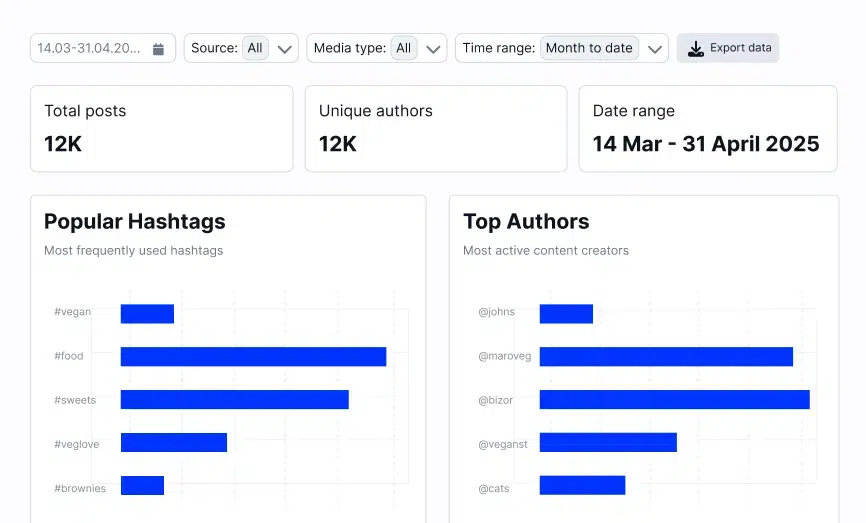
ハッシュタグ(#ばけばけ)での収集は、拡散意図を持ったユーザーの投稿を集めやすい傾向があります。一方、キーワードによる収集は「ハッシュタグをつける習慣がない人」「感想を友人に話すような感覚で書いた投稿」まで広く拾えます。今回収集した550件のうち、ハッシュタグをつけて投稿していたのは全体の3%にも満たなかったことがわかりました。残りの97%は、拡散を意図せず、ただ言葉を残したくて書いた投稿です。
97%
収集した550件のうち、ハッシュタグなしで投稿されていた割合
「自然な会話」を拾うには、ハッシュタグではなくキーワード収集が不可欠
ソーシャルリスニングが「自然な会話を聴く」行為である以上、ハッシュタグよりキーワード収集の方が発話の実態に近いといえます。
550件は、「ばけばけ」のThreads投稿の全体ではありません。筆者の手元の試算では収集期間中1,000〜2000件程度の新規投稿があったと見ていますが、Threads APIの仕様上、全投稿の収集はできません。また今回の収集は放送終了後の4月14日から開始しているのですが、これもAPIの仕様上、収集した投稿には4月14日以前の投稿も2割程度含まれていました。
Threadsキーワード投稿収集に関するAPIによる制限
EmbedSocialはThreads公式APIと連携したサードパーティツールです。そのためAPIの制限によりThreadsキーワード投稿を全数収集はできません。つまり、今回の550件は「世の中のすべての発話」ではなく、「APIの制限内でEmbedSocialが自動収集・蓄積できた、直近のリアルタイムな発話のサンプル」です。
Threads APIによる主な制限(公式ドキュメントより):
今回このドラマをテーマとして扱ったのは、「最終回が終わったはずなのにまだ投稿が続いている」という気づきがきっかけでした。通常、ドラマが終われば話題は急速に下火になります。そのためこの「余熱」の正体を読み解くのが、今回のマイクロ・ソーシャルリスニングの出発点です。
Threadsの声を、自動で集める
EmbedSocialのキーワード収集機能を使えば、指定したキーワードを含むThreads投稿を自動で蓄積できます。収集したデータはCSVエクスポートも可能。ソーシャルリスニングの第一歩を、今すぐ始めましょう。
7日間の無料トライアル中はいつでもキャンセル可
ソーシャルリスニングで投稿データが集まったとき、すぐに内容を読み始めたくなる気持ちはよく分かります。しかし「どんな言葉が多く出ているか」を数える前に、データそのものの性質を把握するステップが欠かせません。今回の550件を例に、最初に確認すべき4つのポイントを整理します。
今回の550件は、2026年4月14日〜6月の約2ヶ月間に収集したデータです。「ばけばけ」の放送が終了した後に収集を開始しているため、このデータは「一般的な視聴者全体の声」ではなく、「ドラマが終わった後もまだThreadsで語り続けている人たちの声」が主に含まれています。
収集期間と開始タイミングを把握するだけで、データの性格が一気に明確になります。同じキーワードでも放送中に収集したデータと放送後では、発話者のプロフィールも内容の傾向も大きく異なるはずです。「いつ・どんな状況の人が語っているか」という文脈が、分析全体の前提になります。
収集データにどれだけ「偏り」があるかを把握することは、その後の分析の精度を大きく左右します。今回の550件を投稿者別に集計すると、次のことがわかりました。
一部の熱心なユーザーが繰り返し投稿しているデータだということがわかります。この分布を確認すると、「キーワードAが何件登場したか」という頻度ベースの定量比較には注意が必要だとわかります。特定のユーザーが同じ表現を繰り返し使うと、その言葉の件数だけが膨らんでしまうからです。
このため今回の分析では、件数の多寡を比較する定量分析より、どんな文脈・感情で語られているかという定性的な読み方に重心を置きます。
前のセクションでも触れたとおり、Threadsで収集したデータにはThreads特有のプラットフォームバイアスがかかっています。Metaはアルゴリズムで政治的・対立的なコンテンツの拡散を抑制する設計を公言しており、ポジティブで長文の投稿が集まりやすい傾向があると推測できます。
このため、Threadsのデータにネガティブな投稿が少なくても、「批判がない」とは言い切れません。批判的な声はそもそも別のプラットフォームに向かっている可能性があります。プラットフォームを選んだ段階でデータの「色」が決まることを、常に意識しておきましょう。
収集に使用するAPIやツールにも制限があります。今回使用したThreads Keyword Search APIは、リアルタイム〜直近の投稿を取得する設計で、過去ログの全件遡及収集には対応していません(公式ドキュメント参照)。
550件は「世の中に存在するすべての発話」ではなく、「この期間にAPIが取得できたサンプル」です。この前提を持って分析に臨むことで、過大な一般化を避け、実際に言えることの輪郭が明確になります。
4つの確認を踏まえると、今回の550件から何が言えて、何を言うべきでないかが整理できます。ソーシャルリスニングの分析に信頼性を持たせるには、この線引きが不可欠です。
「言えること」の列に並ぶのは、すべて定性的・事例的な観察です。特定の傾向や具体的なエピソードの存在は語れますが、「何%のファンが行動変容したか」「どのキーワードが正確に何倍多く使われているか」といった断定的な比較は今回のデータからは導けません。この範囲で読む限り、550件は十分に豊かな情報源です。
データの性質と分析の射程を確認した上で、今回の投稿から読み取れる3つのインサイトを見ていきます。
今回のソーシャルリスニングで最初に注目するのは、ファンや顧客が自発的に生み出した言葉です。製作サイドが用意したキャッチコピーではなく、受け手が自分の言葉で繰り返し使うようになった表現は、そのコンテンツがどれだけ深く刺さったかを示すバロメーターになります。
今回の投稿を通読すると、主人公の本名ではなくファン発の愛称が自然と定着していること、ドラマ由来の特定のセリフが視聴者の日常的なコミュニケーションの中で感嘆詞として使われていること、「ばけばけロス」という終了後の喪失感を表す複合語がファン間で共有されていることに気づきます。
これらは単なる「好き」という感情の表明ではなく、視聴者がコンテンツを自分の内側に取り込んでいることの表れといえます。公式が用意していない言葉が繰り返し登場しているとき、それは顧客が本当に語りたいことのヒントです。1件1件の投稿を丁寧に読み解く定性的なリスニングだからこそ見えてくる発見です。
💡マーケティング活用ポイント:自社の商品やサービスに関するSNS投稿の中に、公式が用意していない言葉が繰り返し登場していないか確認してみてください。ファンや顧客が自発的に使い始める「共通言語」の有無は、コンテンツやブランドへの熱量の深さを測る指標になります。
2つ目は、SNS上の言葉が現実の行動にどう結びついたかです。「感動した」という感想は多くの作品に対して書かれます。しかし「感動して〇〇をした」という行動報告は、それが本物の熱量を持っていたことの証左になります。
今回の投稿データには、現実世界の行動を報告する投稿が明確に含まれています。ロケ地を実際に訪れた体験報告、ドラマに関連した書籍を手に取った記録、楽譜を衝動買いした投稿、再放送を能動的に求める声—そして展示情報をファン自身が他のファンに向けて自発的に拡散している投稿が複数見られます。
最後の点は特に興味深いところです。「展示会に来てください」という製作側からのメッセージではなく、ファンがファンに向けて情報を届けています。このような自発的な拡散は、広告費をかけて設計できるものではありません。コンテンツへの熱量が一定の閾値を超えたときに自然発生する現象です。
💡マーケティング活用ポイント:自社の商品やキャンペーンに関連する投稿の中に「〇〇を買った」「〇〇に行った」という行動報告が含まれているか確認してみてください。行動変容の投稿を発見・収集し、許諾を得た上でサイトに掲載することで、広告より強い説得力を持つソーシャルプルーフになります。
3つ目は、データの「偏り」を逆算してインサイトを導くことです。今回の550件を通読すると、ネガティブな投稿がほとんど見当たりません。これをそのまま「批判がないから優れたコンテンツ」と読むのは早計です。
ここで重要なのは、この偏りがコンテンツの質だけに起因するわけではないという点です。確認③で触れたとおり、Threadsというプラットフォームは炎上が起きにくく、ポジティブで深い言葉が集まりやすい文化があります。つまりこのデータには、プラットフォーム特性とコンテンツへの愛着という二重のポジティブバイアスがかかっています。
これはデメリットではありません。Xであれば賛否が飛び交うテーマでも、Threadsではポジティブで深い言葉が集まりやすい。この特性を知っていれば、Threadsは「自社ブランドをすでに好きな人たちの声を純度高く観察するチャンネル」として戦略的に活用できます。
一方、炎上しているコンテンツや賛否が割れる製品であれば、同じデータ量の中にネガティブな発話が混在します。ポジティブ一色のデータと批判が混在するデータとでは読み方が変わります。バイアスの種類と強度を把握することが、ソーシャルリスニングの解像度を上げます。
💡マーケティング活用ポイント:自社ブランドのSNS投稿がポジティブ一色であっても、「本当に批判がない」とは限りません。プラットフォーム固有のバイアスと発話バイアスを前提に読んだ上で、「それでもこれだけ豊かな言葉が自発的に生まれているのはなぜか」を問うことで、自社の強みの本質が見えてきます。
ここまでの3つのインサイトは、すべて「読む」行為でした。しかし、ソーシャルリスニングはインサイトを得るだけで終わらせる必要はありません。
収集した投稿の中には、ブランドや商品への愛着を綴った投稿、実際に購入・訪問した体験談、思わず共感するリアルな言葉が含まれています。これらはUGC(ユーザー生成コンテンツ)として、ウェブサイトに活用できる可能性を持っています。
EmbedSocialでは、キーワード収集によって発見した投稿に対して、そのままウェブサイトへの掲載許諾をユーザーに申請し、承認された投稿をウィジェットとして自社サイトに埋め込むところまでを一つのプラットフォーム内で行えます。
アンケートの回答文と、実際にユーザーがSNSに書いた言葉では、サイト訪問者への説得力がまるで違います。ソーシャルリスニングで見つけた「本物の声」を、そのままサイトのソーシャルプルーフとして活用することで、コンテンツマーケティングとコンバージョン改善が一本の線でつながります。
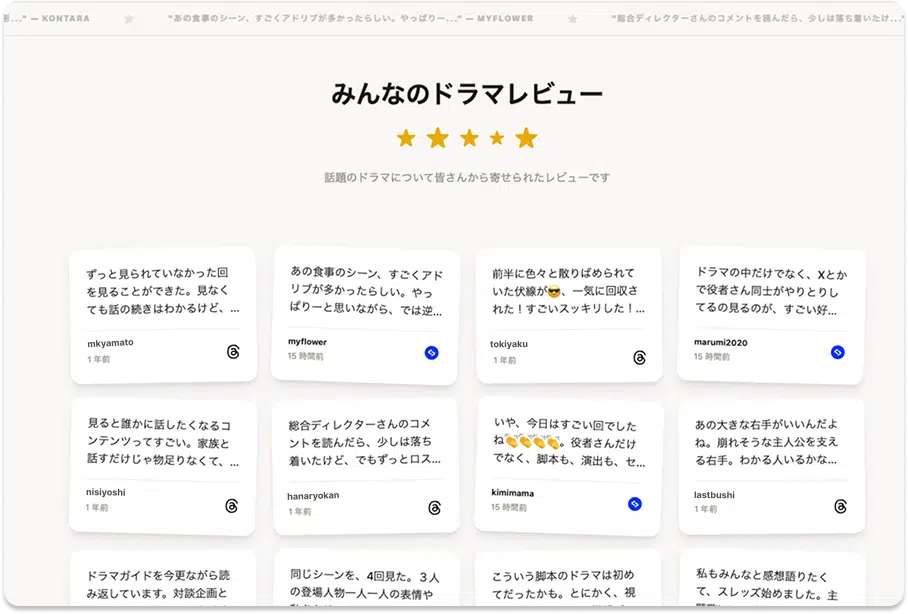
単に投稿を埋め込むだけでなく、最近ではAIを活用してこれらの声をサイトのデザインに最適化して配置する手法(参考:[AIセクションジェネレーターの紹介])も登場しています。
集めた声を、サイトの説得力に変える
EmbedSocialなら、ソーシャルリスニングで発見した良質な投稿を管理し、ウェブサイトに埋め込むところまで一つのツールで完結します。130以上のウィジェットテンプレートから、サイトのデザインに合ったスタイルを選べます。
7日間の無料トライアル中はいつでもキャンセル可
今回は人気ドラマNHK朝ドラ「ばけばけ」を題材に、ソーシャルリスニングの実践的なワークフローを見てきました。
題材はドラマでしたが、「終わってもなぜ語られ続けるのか」という問いの立て方は、自社ブランドにも置き換えられます。新商品の発売後の反響調査、キャンペーン終了後のロイヤリティ計測、競合他社への言及分析など、マーケティングの現場で直面するあらゆる問いにこのワークフローはそのまま使えます。
そして重要なのは、ソーシャルリスニングはリサーチで完結しなくていいということです。EmbedSocialを使えば、収集・確認・分析・UGC活用の一気通貫が一つのプラットフォームで実現します。まずはキーワードひとつで始めてみてください。なお、どのソーシャルリスニングツールが自社に合うか検討中の方はソーシャルリスニングツール比較記事も参考にしてみてください。
あなたのブランドは
どう語られていますか
EmbedSocialのThreadsキーワード収集機能で、今すぐリスニングを始めましょう。収集・分析・UGC活用まで、一つのプラットフォームで完結します。他のSNSでの分析をご希望の場合はお気軽にお問い合わせください。
7日間の無料トライアル中はいつでもキャンセル可